

Récupérer des informations depuis Picasa n’est pas une chose facile, le logiciel est assez limité et ne propose quasiment rien comme fonction d’export de données réutilisables.
Ce que je souhaite faire : extraire les informations brutes de la reconnaissance des visages de la base de données de Picasa. Les noms des personnes, les fichiers sources d’origine et le rectangle associé à chaque visage.
Sur Windows 7, la base de données de Picasa se trouve dans C:\Users\USERNAME\AppData\Local\Google\Picasa2. Dans ce dossier, on trouve principalement des fichiers pmp et des fichiers db. Les fichiers pmp correspondent à des données tabulaires. Chaque fichier pmp contient les données d’une colonne d’une des tables de la base de données. Le nom du fichier pmp correspond à table_colonne.pmp. On va donc avoir 3 tables:
- albumdata, qui contient des informations relatifs aux albums (dossiers et album visages)
- catdata, relatif aux categories (quasiment vide chez moi)
- imagedata, relatif aux images (contient les rectangles et les références des albums)
Comment lire les fichiers PMP ?
Ce sont des fichiers binaires dans le format little-endian. Le header est décrit selon ce tableau :
| Taille | Description |
|---|---|
| 4 octets | constante magique : 0x3fcccccd |
| 2 octets | type de champ (unsigned short) |
| 2 octets | constante : 0x1332 |
| 4 octets | constante : 0x00000002 |
| 2 octets | type de champ (unsigned short) |
| 2 octets | constante: 0x1332 |
| 4 octets | nombre d’entrées (unsigned int) |
Les différents types des valeurs sont :
| Valeur | Description |
|---|---|
| 0x0 | Chaînes de caractères terminées par un caractère nul |
| 0x1 | Unsigned int, 4 octets |
| 0x2 | Dates selon le format Microsoft Variant Time, 8 octets |
| 0x3 | byte field, 1 octet |
| 0x4 | unsigned long, 8 octets |
| 0x5 | unsigned short, 2 octets |
| 0x6 | Chaînes de caractères terminées par un caractère nul |
| 0x7 | unsigned int, 4 octets |
Voir http://sbktech.blogspot.fr/2011/12/picasa-pmp-format.html pour plus d’information sur les fichiers pmp.
Les valeurs qui nous intéresse pour les visages sont facerect (coordonnées du rectangle) et personalbumid (reference de l’album) dans la table imagedata, et les valeurs token (reference de l’album) et name (nom de la personne) dans la table albumdata.
Exemple en retenant que 4 colonnes:
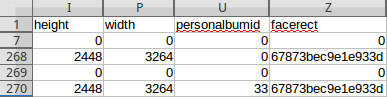
Extrait de la table imagedata de Picasa 3.9
Le rectangle est décrit par une donnée de type rectangle64. Une chaîne de 16 caractères qui contient 4 nombres sur 16 bit. Les nombres, une fois divisés par 2^16-1 (la plus grande valeur possible), sont les coordonnées relatives du point en haut à gauche et du point en bas à droite. Les valeurs absolues sont obtenues en multipliant les abscisses par la largeur de l’image et les ordonnées par la hauteur de l’image.
Exemple :
| nombre d’origine (64 bits) | 0x67873bec9e1e933d | |||
| Découpage en 4 nombres sur 16 bits | 0x6787 | 0x5678 | 0x3b51 | 0x4a89 |
| Conversion en décimal | 26503 | 15340 | 40478 | 37693 |
| Division par 2^16-1 (65535) | 0,4044 | 0,2341 | 0,6176 | 0,5751 |
| Multiplication par la largeur (3264) et la hauteur (2448) | x1=1319 | y1=573 | x2=2016 | y2=1407 |
Avec ces informations, on sait que l’image x a un rectangle de visage de tel taille et qu’il correspond a telle personne mais on ne connait pas le nom du fichier sur le disque dur.
Cette information se trouve dans le fichier thumbindex.db. Ce fichier contient l’ensemble des dossiers et des images indexés dans la base de données de Picasa et l’entrée à la ligne x du fichier thumbindex.db va correspondre à la même image que celle de la ligne x dans la table imagedata.
Comment lire le fichier thumbindex.db ?
Header :
| Taille | Description |
|---|---|
| 4 octets | constante magique : 0x40466666 |
| 4 octets | nombre d’entrées (unsigned int) |
puis chaque ligne est décrit selon le tableau suivant :
| Taille | Description |
|---|---|
| jusqu’au caractère nul | Chaîne de caractères terminée par un caractère nul |
| 26 octets | contenu inutile |
| 4 octets | index de l’entrée |
Chaque ligne va être soit un dossier avec le chemin complet et une valeur d’index particulière (4294967295), soit une image avec juste le nom du fichier et un index qui va pointer vers le dossier correspondant et qui va permettre de reconstruire le nom complet de l’image.

Extrait du fichier thumbindex.db de Picasa 3.9
Dans l’exemple, l’image 266 est dans le dossier 5.
Voir http://projects.mindtunnel.com/picasa3meta/docs/picasa3meta.thumbindex.ThumbIndex-class.html pour plus d’information sur le fichier thumbindex.db.
Si l’on fait la fusion de la table imagedata et des données contenu dans thumbindex.db on se rend compte que pour une image donnée, on va avoir le nom du fichier sur le disque dur, le rectangle du visage mais pas de référence d’album !
Picasa va en fait stocker une image virtuelle en plus pour stocker cette donnée. Dans l’exemple précédent, l’image virtuelle 268 (qui n’a pas de nom de fichier) va contenir les informations sur le visage d’une personne qui se trouve dans l’image 266. Le rectangle sur l’image 266 va contenir l’ensemble des rectangles (quand l’image a plus d’un visage identifié, sinon le rectangle va être le même que celui de la personne). Il suffit donc de lire la référence de l’album de l’image 268 et de l’associer au non de fichier de l’image 266.
J’ai créer un programme qui va lire toutes ces informations et les stocker dans des fichiers csv. Un fichier par table pmp et un fichier pour les visages. Le programme peut aussi créer des vignettes de visage si imagemagick est installé (et que l’application convert soit dans le path).
Comment utiliser le programme qui va lire la base de données de Picasa ?
Il y a en fait 2 programmes. Un, appelé PMPDB qui va convertir les table pmp en fichier csv et un, appelé PicasaFaces qui va créer un fichier csv lisible qui va contenir toutes les informations sur les visages et va créer les vignettes des visages.
Usage:
java -classpath ".:bin/:commons-cli-1.2.jar" PMPDB -folder "/path/to/PicasaDB/Picasa2/db3/" -output ./OutputFolder
java -classpath ".:bin/:commons-cli-1.2.jar:commons-io-2.4.jar" PicasaFaces -folder "/path/to/PicasaDB/Picasa2/db3/" -output ./OutputFolder -replaceRegex C: -replacement /media/HardDrive -convert /path/to/convert(.exe)
Si la ligne de commande contient l’argument -convert, alors imagemagick va créer toutes les vignettes (dans le dossier de destination avec un dossier pour chaque personne). Une modification du chemin des images peut être effectuée si les images ont changées de place par rapport aux informations contenu dans la base de données (dans l’exemple « C: » sera remplacé par « /media/HardDrive ».
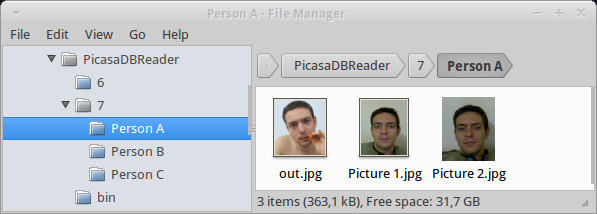
Résultat de l’extraction des visages de Picasa 3.9
Les sources sont disponible sur github : https://github.com/skisoo/PicasaDBReader
Fonctionne sous Windows et Linux.
Bonjour Skisoo, ton post sur comment lire la base de données est très intéressante et m’a été très utiles.
J’utilise présentement Picasa pour un projet et je me demandais si tu avais une solution à un problème qui s’est récemment présenté.
J’ai un grand nombre de photo de style passeport de plusieurs personnes (600 000 individus) chaque photo est nommé d’un numéro alphanumérique. Dans une base de donnée j’ai l’identification de la personne correspondant au numéro alphanumérique. Il est impossible d’identifier manuellement chaque photo le délai serait incroyable.
As-tu une idée ou une piste de solution pour que j’écrive un scrpt afin de nommer automatiquement chaque visage.
merci
Si j’ai bien compris, tu as d’un côté une base de données liant le nom du fichier de l’image (numéro alphanumérique) et le nom de la personne. Et tu souhaites renommer chaque image avec le nom de la personne ? Si c’est le cas, pas besoin d’utiliser Picasa, un petit script suffit. Si tu souhaite identifier ces personnes dans Picasa, il faut passer par une opération manuelle…
Note que tu peux faire tourner la reconnaissance de personne dans Picasa, ensuite extraire les coordonnées des visages (qui sont liées au nom du fichier) et faire correspondre les visages aux personnes via le numéro alphanumérique.
J’espère que cela répond à ta question.
Tu as bien cerné le problème, tu viens de confirmer ce que je croyais. Merci de ton aide. Un travail de longue haleine s’amorce.
Crois-tu qu’il est possible de faire des ajouts manuellement dans la base de données?
Pour le logiciel sous Windows, non. Pour la version web, il y a une API qui pourrait peut être servir.
Merci
Bonjour,
J’ai utilisé avec succès PicasaFaces il y a quelques jours. Depuis j’ai complété la reconnaissance de visages de Picasa et j’ai un problème en voulant exploiter le DB3 mis à jour.
Exception in thread « main » java.lang.IndexOutOfBoundsException: Index: 22486, Size: 22485
at java.util.ArrayList.RangeCheck(ArrayList.java:547)
at java.util.ArrayList.get(ArrayList.java:322)
at PicasaFaces.gatherImages(PicasaFaces.java:142)
at PicasaFaces.main(PicasaFaces.java:117)
En tout cas, bravo pour cette appli.
J’ai l’impression que le programme essaie de lire un peu trop de lignes à la fin du fichier (dans l’exemple personne 22486 alors que ça s’arrête à 22485) ou sinon les 2 programmes n’ont pas été lancés sur les mêmes données.
y a-t-il un moyen simple (je ne suis pas informaticien) de supprimer ce que j’appelle les contacts fantômes : quand on tape un nom pour nommer un visage, le même contact est proposé en plusieurs fois sans la vignette (en plus du bon qui est proposé) alors qu’on ne peut pas les supprimer dans « gestionnaire de contact » et qu’ils n’existent pas non plus dans la liste des contacts gmail ou google?
merci
J’en ai aucune idée.